本文主要通过源码分析了 etcd v3 版本 MVCC 的具体实现。
分析基于 etcd v3.5.1版本。
原文作者: 意琦行
原文链接: etcd教程(十二)—etcd mvcc 源码分析 | 指月小筑|意琦行的个人博客
1. 概述
为什么选择MVCC
etcd v3 版本为了解决 v2 版本的 并发性能问题和 watch 机制可靠性问题,因此选择了 MVCC 机制。
大致实现
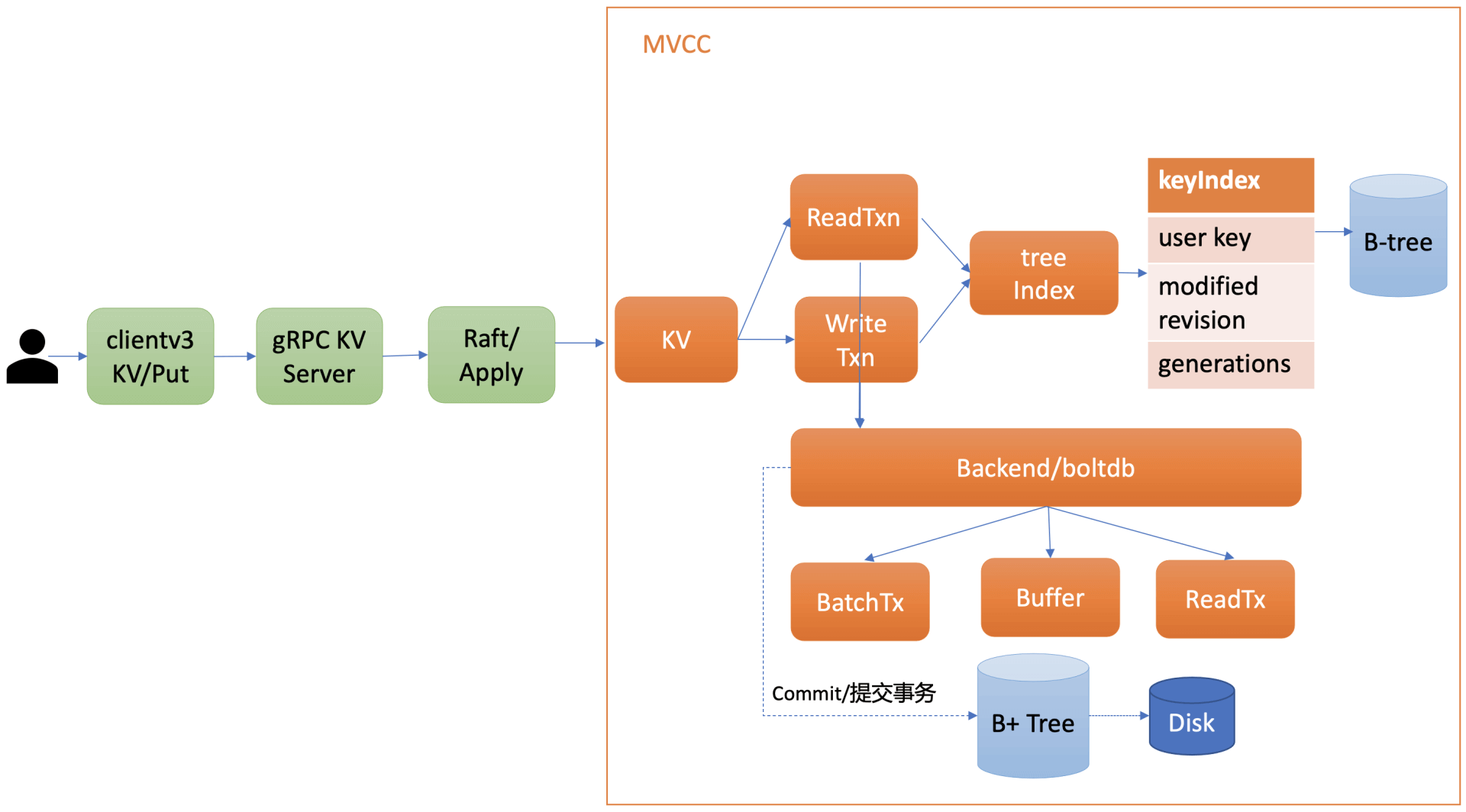
etcd 借助 blotdb,以 revision 为 key,在 blotdb 中存储了 key 的多版本数据。
借助 treeIndex 模块,在内存中以 BTree 构建了 keyIndex 结构来关联 key 及其对应的 revisions。
用户操作时,先根据 key 查询 keyIndex 找到对应的 revisions,然后再操作 blotdb。
整体架构
2. treeIndex 模块
相关结构
1
2
3
4
5
| type treeIndex struct {
sync.RWMutex
tree *btree.BTree
lg *zap.Logger
}
|
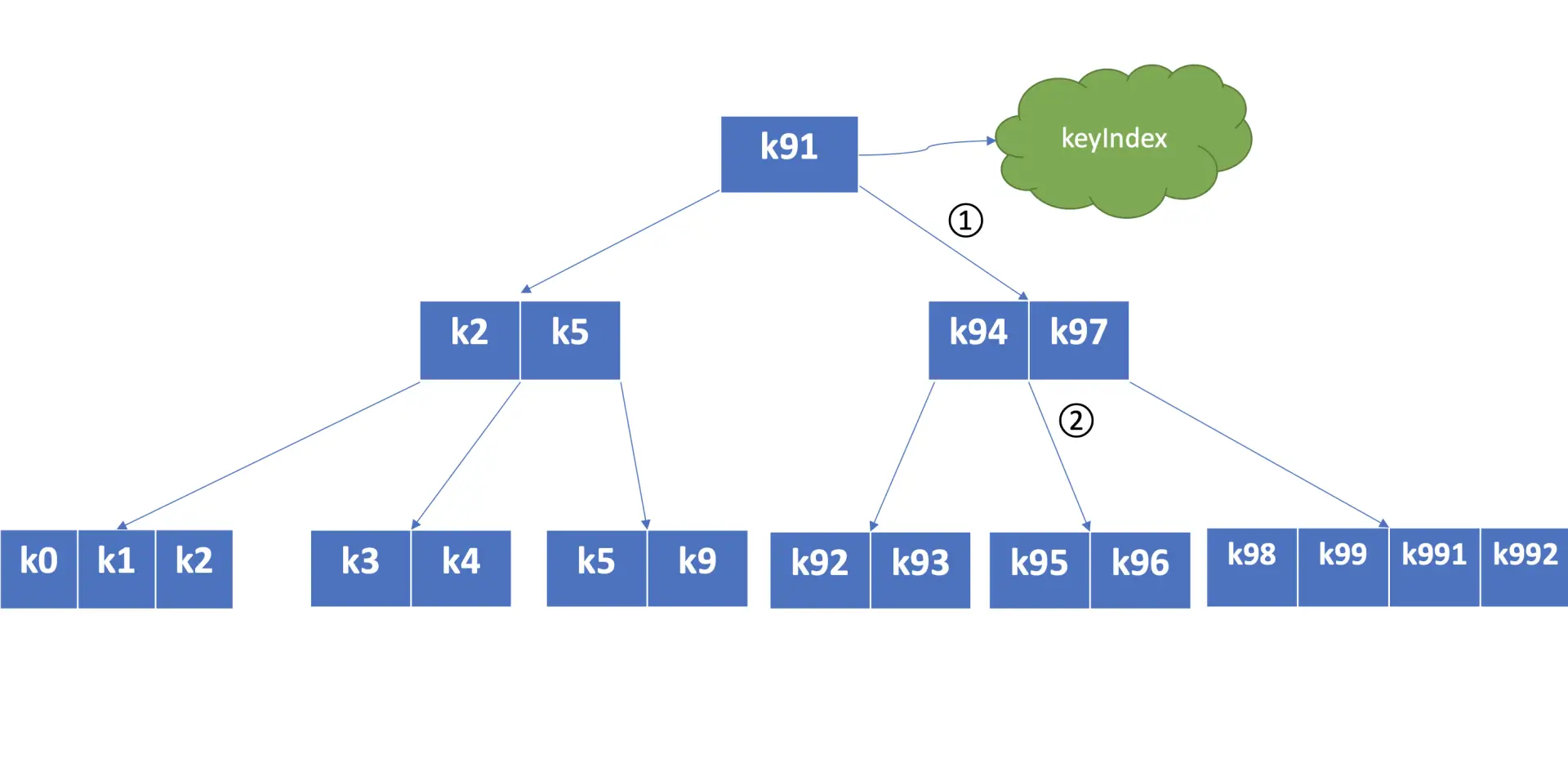
可以看到是基于 Google 开源的 BTree 实现的。
在 treeIndex 中,每个节点的 key 是一个 keyIndex 结构,etcd 就是通过它保存了用户的 key 与版本号的映射关系。
每个 B-tree 节点保存的具体内容如下
1
2
3
4
5
| type keyIndex struct {
key []byte // 用户的key名称
modified revision // 最后一次修改key时的etcd版本号
generations []generation // generation保存了一个key若干代版本号信息,每代中包含对key的多次修改的版本号列表
}
|
keyIndex 中包含用户的 key、最后一次修改 key 时的 etcd 版本号、key 的若干代(generation)版本号信息,每代中包含对 key 的多次修改的版本号列表。
generations 表示一个 key 从创建到删除的过程,每代对应 key 的一个生命周期的开始与结束。
- 当你第一次创建一个 key 时,会生成第 0 代,后续的修改操作都是在往第 0 代中追加修改版本号。
- 当你把 key 删除后,它就会生成新的第 1 代,一个 key 不断经历创建、删除的过程,它就会生成多个代。
generation 结构详细信息如下:
1
2
3
4
5
| type generation struct {
ver int64 //表示此key的修改次数
created revision //表示generation结构创建时的版本号
revs []revision //每次修改key时的revision追加到此数组
}
|
generation 结构中包含此 key 的修改次数、generation 创建时的版本号、对此 key 的修改版本号记录列表。
你需要注意的是版本号(revision)并不是一个简单的整数,而是一个结构体。revision 结构及含义如下:
1
2
3
4
| type revision struct {
main int64 // 一个全局递增的主版本号,随put/txn/delete事务递增,一个事务内的key main版本号是一致的
sub int64 // 一个事务内的子版本号,从0开始随事务内put/delete操作递增
}
|
revision 包含 main 和 sub 两个字段:
- main 是全局递增的版本号,它是个 etcd 逻辑时钟,随着 put/txn/delete 等事务递增。
- sub 是一个事务内的子版本号,从 0 开始随事务内的 put/delete 操作递增。
比如启动一个空集群,全局版本号默认为 1,执行下面的 txn 事务,它包含两次 put、一次 get 操作,那么按照我们上面介绍的原理,全局版本号随读写事务自增,因此是 main 为 2,sub 随事务内的 put/delete 操作递增,因此 key hello 的 revison 为{2,0},key world 的 revision 为{2,1}。
相关操作
treeIndex 模块具体实现的方法如下所示:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| // server/storage/mvcc/index.go 25 行
type index interface {
Get(key []byte, atRev int64) (rev, created revision, ver int64, err error)
Range(key, end []byte, atRev int64) ([][]byte, []revision)
Revisions(key, end []byte, atRev int64, limit int) ([]revision, int)
CountRevisions(key, end []byte, atRev int64) int
Put(key []byte, rev revision)
Tombstone(key []byte, rev revision) error
RangeSince(key, end []byte, rev int64) []revision
Compact(rev int64) map[revision]struct{}
Keep(rev int64) map[revision]struct{}
Equal(b index) bool
Insert(ki *keyIndex)
KeyIndex(ki *keyIndex) *keyIndex
}
|
简单分析以下 Get 方法:
1
2
3
4
5
6
7
8
9
10
| // server/storage/mvcc/index.go 69 行
func (ti *treeIndex) Get(key []byte, atRev int64) (modified, created revision, ver int64, err error) {
keyi := &keyIndex{key: key}
ti.RLock()
defer ti.RUnlock()
if keyi = ti.keyIndex(keyi); keyi == nil {
return revision{}, revision{}, 0, ErrRevisionNotFound
}
return keyi.get(ti.lg, atRev)
}
|
只是查询,所以加的是 ReadLock。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
| // server/storage/mvcc/index.go 137 行
func (ki *keyIndex) get(lg *zap.Logger, atRev int64) (modified, created revision, ver int64, err error) {
if ki.isEmpty() {
lg.Panic(
"'get' got an unexpected empty keyIndex",
zap.String("key", string(ki.key)),
)
}
// 首先找到对应的 Generation
g := ki.findGeneration(atRev)
if g.isEmpty() {
return revision{}, revision{}, 0, ErrRevisionNotFound
}
// 然后根据版本号大小关系找到对应位置
n := g.walk(func(rev revision) bool { return rev.main > atRev })
if n != -1 {
return g.revs[n], g.created, g.ver - int64(len(g.revs)-n-1), nil
}
return revision{}, revision{}, 0, ErrRevisionNotFound
}
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
| // server/storage/mvcc/index.go 280 行
func (ki *keyIndex) findGeneration(rev int64) *generation {
lastg := len(ki.generations) - 1
cg := lastg
// 比较简单,就是一个 for 循环
for cg >= 0 {
if len(ki.generations[cg].revs) == 0 {
cg--
continue
}
g := ki.generations[cg]
if cg != lastg {
if tomb := g.revs[len(g.revs)-1].main; tomb <= rev {
return nil
}
}
// 找的是小于等于的版本号
if g.revs[0].main <= rev {
return &ki.generations[cg]
}
cg--
}
return nil
}
|
这个for循环是倒着循环的,即从最新的 generations 开始遍历。这也算是一个小的优化吧,毕竟查询的时候就算是历史版本也是最近的版本,这样倒叙循环能省掉一些无效的遍历,会快一些。
找到对应的 generation 后就进入 walk 逻辑:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| /*
n := g.walk(func(rev revision) bool { return rev.main > atRev })
if n != -1 {
return g.revs[n], g.created, g.ver - int64(len(g.revs)-n-1), nil
}
*/
func (g *generation) walk(f func(rev revision) bool) int {
l := len(g.revs)
for i := range g.revs {
ok := f(g.revs[l-i-1])
if !ok {
return l - i - 1
}
}
return -1
}
|
walk 就是行走的意思,可以理解为遍历每个元素,都执行这个操作。
这也是 Go 中常用的一种写法。
实现也很简单,就是一个for循环,找到对应的位置并返回。
这就是 treeIndex 模块的 Get 方法实现:
- 通过第一次 for 循环找到对应 generation
- 再通过第二次 for 循环找到对应 revision
然后就是根据 revision 为 key,去 blotdb 中查询对应的 value 了。
3. MVCC 模块
1. put
一个 put 命令流程如下图所示:
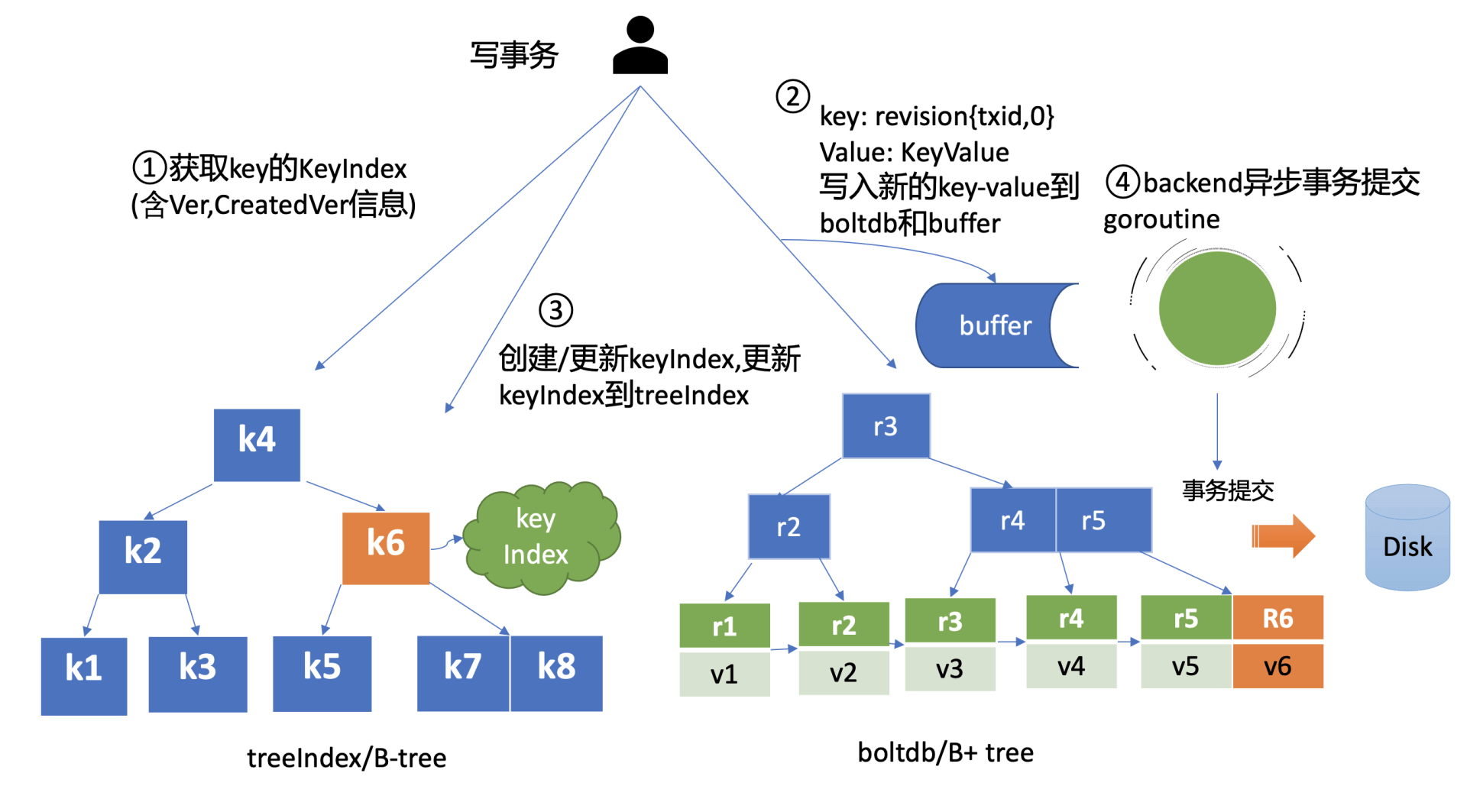
共分为以下几个步骤:
查询 keyIndex
- keyIndex 中存储了 key 的创建版本号、修改的次数等信息,这些信息在事务中发挥着重要作用,因此会存储在 boltdb 的 value 中。
写入 boltdb
更新 treeIndex
持久化
- 为了提升性能,具体实现为异步批量操作
- 为了提升 etcd 的写吞吐量、性能,一般情况下(默认堆积的写事务数大于 1 万才在写事务结束时同步持久化),数据持久化由 Backend 的异步 goroutine 完成,它通过事务批量提交,定时将 boltdb 页缓存中的脏数据提交到持久化存储磁盘中。
源码如下:
1
2
3
4
5
| // server/storage/mvcc/kvstore_txn.go 108 行
func (tw *storeTxnWrite) Put(key, value []byte, lease lease.LeaseID) int64 {
tw.put(key, value, lease)
return tw.beginRev + 1
}
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
| // server/storage/mvcc/kvstore_txn.go 182 行
func (tw *storeTxnWrite) put(key, value []byte, leaseID lease.LeaseID) {
rev := tw.beginRev + 1
c := rev
oldLease := lease.NoLease
// 1.查询keyIndex
_, created, ver, err := tw.s.kvindex.Get(key, rev)
if err == nil {
// 覆盖创建rev
c = created.main
oldLease = tw.s.le.GetLease(lease.LeaseItem{Key: string(key)})
}
// 序列化rev信息
ibytes := newRevBytes()
idxRev := revision{main: rev, sub: int64(len(tw.changes))}
revToBytes(idxRev, ibytes)
ver = ver + 1
// 实例化KeyValue
kv := mvccpb.KeyValue{
Key: key,
Value: value,
CreateRevision: c,
ModRevision: rev,
Version: ver,
Lease: int64(leaseID),
}
d, err := kv.Marshal()
if err != nil {
tw.storeTxnRead.s.lg.Fatal(
"failed to marshal mvccpb.KeyValue",
zap.Error(err),
)
}
// 2.写blotdb
tw.tx.UnsafeSeqPut(schema.Key, ibytes, d)
// 3.更新keyIndex
tw.s.kvindex.Put(key, idxRev)
tw.changes = append(tw.changes, kv)
// lease 相关更新
// 若存在旧lease则移除
if oldLease != lease.NoLease {
if tw.s.le == nil {
panic("no lessor to detach lease")
}
err = tw.s.le.Detach(oldLease, []lease.LeaseItem{{Key: string(key)}})
if err != nil {
tw.storeTxnRead.s.lg.Error(
"failed to detach old lease from a key",
zap.Error(err),
)
}
}
// 若本次指定了 lease则关联上
if leaseID != lease.NoLease {
if tw.s.le == nil {
panic("no lessor to attach lease")
}
err = tw.s.le.Attach(leaseID, []lease.LeaseItem{{Key: string(key)}})
if err != nil {
panic("unexpected error from lease Attach")
}
}
}
|
具体逻辑和前面分析的一致,不过这里需要注意的是 Lease 相关的处理。PUT 时会移除旧的 Lease 和 key 的关联。这就意味着如果想要一直让 key 关联 lease 的话需要每次 PUT 都指定Lease才行。
这和 Redis 的 TTL 还是有很大的不同
然后作者发现一个问题,如果更新的时候提交一个相同的 leaseID,会先 Detach 然后又 Attach 上去,于是提了个 PR,现在已经合并进主干了。
2. get
具体流程如下:
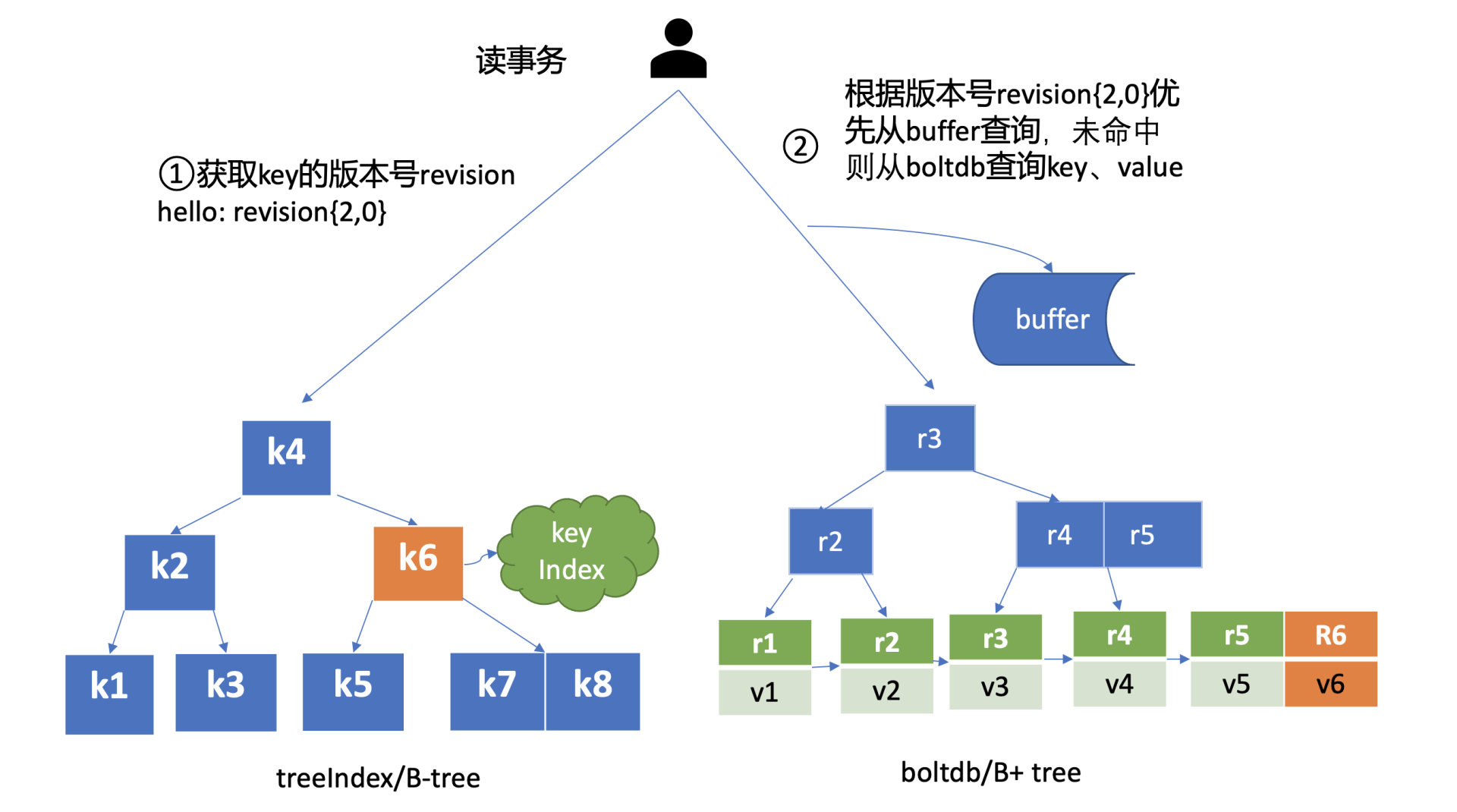
- 查询版本号
- 查询 blotdb
具体如下:
1
2
3
4
| // server/storage/mvcc/kvstore_txn.go 61行
func (tr *storeTxnRead) Range(ctx context.Context, key, end []byte, ro RangeOptions) (r *RangeResult, err error) {
return tr.rangeKeys(ctx, key, end, tr.Rev(), ro)
}
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
| // server/storage/mvcc/kvstore_txn.go 127行
func (tr *storeTxnRead) rangeKeys(ctx context.Context, key, end []byte, curRev int64, ro RangeOptions) (*RangeResult, error) {
rev := ro.Rev
if rev > curRev {
return &RangeResult{KVs: nil, Count: -1, Rev: curRev}, ErrFutureRev
}
// 若没指定或指定了错误的版本号就会默认查最新的一个版本
if rev <= 0 {
rev = curRev
}
// 1.查找 revisions
// 这里如果当前查询的版本号比compactMainRev小说明这个版本已经被回收了 直接返回错误
if rev < tr.s.compactMainRev {
return &RangeResult{KVs: nil, Count: -1, Rev: 0}, ErrCompacted
}
if ro.Count {
total := tr.s.kvindex.CountRevisions(key, end, rev)
tr.trace.Step("count revisions from in-memory index tree")
return &RangeResult{KVs: nil, Count: total, Rev: curRev}, nil
}
// 否则就查询比当前版本号大的所有版本号
revpairs, total := tr.s.kvindex.Revisions(key, end, rev, int(ro.Limit))
tr.trace.Step("range keys from in-memory index tree")
if len(revpairs) == 0 {
return &RangeResult{KVs: nil, Count: total, Rev: curRev}, nil
}
limit := int(ro.Limit)
if limit <= 0 || limit > len(revpairs) {
limit = len(revpairs)
}
kvs := make([]mvccpb.KeyValue, limit)
revBytes := newRevBytes()
// 2.查询 blotdb
// 然后根据上面查到的版本号循环去blotdb中查找对应value
for i, revpair := range revpairs[:len(kvs)] {
select {
case <-ctx.Done():
return nil, ctx.Err()
default:
}
revToBytes(revpair, revBytes)
_, vs := tr.tx.UnsafeRange(schema.Key, revBytes, nil, 0)
if len(vs) != 1 {
tr.s.lg.Fatal(
"range failed to find revision pair",
zap.Int64("revision-main", revpair.main),
zap.Int64("revision-sub", revpair.sub),
)
}
if err := kvs[i].Unmarshal(vs[0]); err != nil {
tr.s.lg.Fatal(
"failed to unmarshal mvccpb.KeyValue",
zap.Error(err),
)
}
}
tr.trace.Step("range keys from bolt db")
return &RangeResult{KVs: kvs, Count: total, Rev: curRev}, nil
}
|
根据源码可以知道,当我们没有指定 Revision 时,etcd 会默认查询最新版本的数据。
3. del
当执行 del 命令时 etcd 实现的是延期删除模式,原理与 key 更新类似。
与更新 key 不一样之处在于:
- 一方面,生成的 boltdb key 版本号{4,0,t}追加了删除标识(tombstone, 简写 t),boltdb value 变成只含用户 key 的 KeyValue 结构体。
- 另一方面 treeIndex 模块也会给此 key hello 对应的 keyIndex 对象,追加一个空的 generation 对象,表示此索引对应的 key 被删除了。
当你再次查询 hello 的时候,treeIndex 模块根据 key hello 查找到 keyindex 对象后,若发现其存在空的 generation 对象,并且查询的版本号大于等于被删除时的版本号,则会返回空。
那么 key 打上删除标记后有哪些用途呢?什么时候会真正删除它呢?
- 一方面删除 key 时会生成 events,Watch 模块根据 key 的删除标识,会生成对应的 Delete 事件。
- 另一方面,当你重启 etcd,遍历 boltdb 中的 key 构建 treeIndex 内存树时,你需要知道哪些 key 是已经被删除的,并为对应的 key 索引生成 tombstone 标识。
而真正删除 treeIndex 中的索引对象、boltdb 中的 key 是通过压缩 (compactor) 组件异步完成。
正因为 etcd 的删除 key 操作是基于以上延期删除原理实现的,因此只要压缩组件未回收历史版本,我们就能从 etcd 中找回误删的数据。
具体如下:
1
2
3
4
5
6
7
| // server/storage/mvcc/kvstore_txn.go 101行
func (tw *storeTxnWrite) DeleteRange(key, end []byte) (int64, int64) {
if n := tw.deleteRange(key, end); n != 0 || len(tw.changes) > 0 {
return n, tw.beginRev + 1
}
return 0, tw.beginRev
}
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| // server/storage/mvcc/kvstore_txn.go 247行
func (tw *storeTxnWrite) deleteRange(key, end []byte) int64 {
rrev := tw.beginRev
if len(tw.changes) > 0 {
rrev++
}
// 1.先在 keyIndex 中找到 blotdb 中对应的key
keys, _ := tw.s.kvindex.Range(key, end, rrev)
if len(keys) == 0 {
return 0
}
// 2. 循环删除
for _, key := range keys {
tw.delete(key)
}
return int64(len(keys))
}
|
具体 blotdb 删除逻辑如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
| // server/storage/mvcc/kvstore_txn.go 262行
func (tw *storeTxnWrite) delete(key []byte) {
ibytes := newRevBytes()
idxRev := revision{main: tw.beginRev + 1, sub: int64(len(tw.changes))}
revToBytes(idxRev, ibytes)
// 1.标记删除 blotdb
// 在 blotdb 的 key上追加tombstone标识(标记删除)
ibytes = appendMarkTombstone(tw.storeTxnRead.s.lg, ibytes)
kv := mvccpb.KeyValue{Key: key}
d, err := kv.Marshal()
if err != nil {
tw.storeTxnRead.s.lg.Fatal(
"failed to marshal mvccpb.KeyValue",
zap.Error(err),
)
}
// 因为是标记删除,所以这里调用的是 put而不是delete
tw.tx.UnsafeSeqPut(schema.Key, ibytes, d)
// 2.处理keyIndex
err = tw.s.kvindex.Tombstone(key, idxRev)
if err != nil {
tw.storeTxnRead.s.lg.Fatal(
"failed to tombstone an existing key",
zap.String("key", string(key)),
zap.Error(err),
)
}
tw.changes = append(tw.changes, kv)
// 3.如果还有关联的 lease,则移除关联
item := lease.LeaseItem{Key: string(key)}
leaseID := tw.s.le.GetLease(item)
if leaseID != lease.NoLease {
err = tw.s.le.Detach(leaseID, []lease.LeaseItem{item})
if err != nil {
tw.storeTxnRead.s.lg.Error(
"failed to detach old lease from a key",
zap.Error(err),
)
}
}
}
|
对 keyIndex 的处理如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| // server/storage/mvcc/index.go 165 行
func (ti *treeIndex) Tombstone(key []byte, rev revision) error {
keyi := &keyIndex{key: key}
ti.Lock()
defer ti.Unlock()
// 如果 key 不存在,返回一个错误
item := ti.tree.Get(keyi)
if item == nil {
return ErrRevisionNotFound
}
ki := item.(*keyIndex)
return ki.tombstone(ti.lg, rev.main, rev.sub)
}
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
| // server/storage/mvcc/key_index.go 119行
func (ki *keyIndex) tombstone(lg *zap.Logger, main int64, sub int64) error {
if ki.isEmpty() {
lg.Panic(
"'tombstone' got an unexpected empty keyIndex",
zap.String("key", string(ki.key)),
)
}
if ki.generations[len(ki.generations)-1].isEmpty() {
return ErrRevisionNotFound
}
// 首先是把当前删除也作为一个版本号写进入
ki.put(lg, main, sub)
// 然后新增了一个 generation,后续的操作就会记录到这个新的 generation 里
ki.generations = append(ki.generations, generation{})
// 这个是用于 prometheus 测量数据用的,标记着 etcd 中的 key的数量
// 虽然是标记删除但还是把这个计数-1了,等后续这个key被再次创建的时候又会+1
keysGauge.Dec()
return nil
}
|
4. 小结
blotdb 中以 revision 作为 key,以存储多版本数据。
treeIndex 模块中构建 BTree 结构的 keyIndex 以关联 key 和 revisions 的关系,加快查询速度。
当你未带版本号查询 key 时,etcd 返回的是 key 最新版本数据。
删除一个数据时,etcd 并未真正删除它,而是基于 lazy delete 实现的异步删除,真正删除 key 是通过 etcd 的压缩组件去异步实现的。
- 具体为 del 时会在 keyIndex 中追加一个空的 generation
- 若查询时发送有空的 generation 且查询版本号大于 keyIndex 中的版本号则说明该 key 已经被删除了,当前查询会返回空数据
5. 参考
https://github.com/etcd-io/etcd